Back in the day, Joel Spolsky had a very influential tech blog, and one of the pieces he wrote described the kind of software developer he liked to hire, one who was "Smart, and gets things done." He later turned it into a book (http://www.amazon.com/Smart-Gets-Things-Done-Technical/dp/1590598385). Steve Yegge, who was also a very influential blogger in the oughties, wrote a followup, in which he tackled the problem of how you find and hire developers who are smarter than you. Given the handicaps of human psychology, how do you even recognize what you're looking at? His rubric for identifying these people (flipping Spolsky's) was "Done, and gets things smart". That is, this legendary "10X" developer was the sort who wouldn't just get done the stuff that needed to be done, but would actually anticipate what needed to be done. When you asked them to add a new feature, they'd respond that it was already done, or that they'd just need a few minutes, because they'd built things in such a way that adding your feature that you just thought of would be trivial. They wouldn't just finish projects, they'd make everything better—they'd create code that other developers could easily build upon. Essentially, they'd make everyone around them more effective as well.
I've been thinking a lot about this over the last few months, as I've worked on finishing a project started by Sebastian Rahtz: integrating support for the new "Pure ODD" syntax into the TEI Stylesheets. The idea is to have a TEI syntax for describing the content an element can have, rather than falling back on embedded RelaxNG. Lou Burnard has written about it here: https://jtei.revues.org/842. Sebastian wrote the XSLT Stylesheets and the supporting infrastructure which are both the reference implementation for publishing TEI and the primary mechanism by which the TEI Guidelines themselves are published. And they are the basis of TEI schema generation as well. So if you use TEI at all, you have Sebastian to thank.
Picking up after Sebastian's retirement last year has been a tough job. It was immediately obvious to me just how much he had done, and had been doing for the TEI all along. When Gabriel Bodard described to me how the TEI Council worked, after I was elected for the first time, he said something like: "There'll be a bunch of people arguing about how to implement a feature, or even whether it can be done, and then Sebastian will pipe up from the corner and say 'Oh, I just did it while you were talking.'" You only have to look at the contributors pages for both the TEI and the Stylesheets to see that Sebastian was indeed operating at a 10X level. Quietly, without making any fuss about it, he's been making the TEI work for many years.
The contributions of software developers are often easily overlooked. We only notice when things don't work, not when everything goes smoothly, because that's what's supposed to happen, isn't it? Even in Digital Humanities, which you'd expect to be self-aware about this sort of thing, the intellectual contributions of software developers can often be swept under the rug. So I want to go on record, shouting a loud THANK YOU to Sebastian for doing so much and for making the TEI infrastructure smart.
*****
UPDATE 2016-3-16
I heard the sad news last night that Sebastian passed away yesterday on the Ides of March. We are much diminished by his loss.
Monday, February 22, 2016
Friday, October 25, 2013
DH Data Talk
Last night I was on a panel organized by Duke Libraries' Digital Scholarship group. The panelists each gave some brief remarks and then we had what I thought was a really productive and interesting discussion. The following are my own remarks, with links to my slides (opens a new tab). In my notes, //slide// means click forward (not always to a new slide, maybe just a fragment).
This is me, and I work //slide// for this outfit. I'm going to talk just a little about a an old project and a new one, and not really give any details about either, but surface a couple of problems that I hope will be fodder for discussion. //slide// The old project is Papyri.info and publishes all kinds of data about ancient documents mostly written in ink on papyrus. The new one, Integrating Digital Epigraphies (IDEs), is about doing much the same thing for ancient documents mostly incised on stone.
If I had to characterize (most of) the work I'm doing right now, I'd say I'm working on detecting and making machine-actionable the scholarly links and networks embedded in a variety of related projects, with data sources including plain text, XML, Relational Databases, web services, and images. These encompass critical editions of texts (often in large corpora), bibliography, citations in books and articles, images posted on Flickr, and databases of texts. You could think of what I'm doing as recognizing patterns and then converting those into actual links; building a scaffold for the digital representation of networks of scholarship. This is hard work. //slide// It's hard because while superficial patterns are easy to detect, //slide// without access to the system of thought underlying those patterns (and computers can't do that yet—maybe never), those patterns are really just proxies kicked up by the underlying system. They don't themselves have meaning, but they're all you have to hold on to. //slide// Our brains (with some prior training) are very good at navigating this kind of mess, but digital systems require explicit instructions //slide// —though granted, you can sometimes use machine learning techniques to generate those.
When I say I'm working on making scholarly networks machine actionable, I'm talking about encoding as digital relations the graph of references embedded in these books, articles and corpora, and in the metadata of digital images. There are various ways one might do this, and the one we're most deeply into right now is called //slide// RDF. RDF models knowledge as a set of simple statements in the form Subject, Predicate, Object. //slide// So A cites B, for example. RDF is a web technology, so all three of these elements may be URIs that you could open in a web browser, //slide// and if you use URIs in RDF, then the object of one statement can be the subject of another, and so on. //slide// So you can use it to model logical chains of knowledge. Now notice that these statements are axioms. You can't qualify them, at least not in a fine-grained way. So this works great in a closed system (papyri.info), where we get to decide what the facts are; it's going to be much more problematic in IDEs, where we'll be coordinating data from at least half a dozen partners. Partners who may not agree on everything. //slide// What I've got is the same problem from a different angle—I need to model a big pile of opinion but all I have to do it with are facts.
Part of the solution to these problems has to be about learning how to make the insertion of machine-actionable links and facts (or at least assertions), part of—that is, a side-effect of—the normal processes of resource creation and curation. But it also has to be about building systems that can cope with ambiguity and opinion.
Wednesday, September 11, 2013
Outside the tent
Yesterday was a bad day. I’m chasing a messed-up software problem whose main symptom is the application consuming all available memory and then falling over without leaving a useful stacktrace. Steve Ramsay quit Twitter. A colleague I have huge respect for is leaving a project that’s foundational and is going to be parked because of it (that and the lack of funding). This all sucks. As I said on Twitter, it feels like we’ve hit a tipping point. I think DH has moved on and left a bunch of us behind. I have to start this off by saying that I really have nothing to complain about, even if some of this sounds like whining. I love my job, my colleagues, and I’m doing my best to get over being a member of a Carolina family working at Duke :-). I’m also thinking about these things a lot in the run up to Speaking in Code.
For some time now I’ve been feeling uneasy about how I should present myself and my work. A few years ago, I’d have confidently said I work on Digital Humanities projects. Before that, I was into Humanities Computing. But now? I’m not sure what I do is really DH any more. I suspect the DH community is no longer interested in the same things as people like me, who write software to enable humanistic inquiry and also like to think (and when possible write and teach) about how that software instantiates ideas about the data involved in humanistic inquiry. On one level, this is fine. Time, and academic fashion, marches on. It is a little embarrassing though given that I’m a “Senior Digital Humanities Programmer”.
Moreover, the field of “programming” daily spews forth fresh examples of unbelievable, poisonous, misogyny and seems largely incapable of recognizing what a shitty situation its in because of it.
The tech industry is in moral crisis. We live in a dystopian, panoptic geek revenge fantasy infested by absurd beliefs in meritocracy, full of entrenched inequalities, focused on white upper-class problems, inherently hostile to minorities, rife with blatant sexism and generally incapable of reaching anyone beyond early adopter audiences of people just like us. (from https://medium.com/about-work/f6ccd5a6c197)
I think communities who fight against this kind of oppression, like #DHPoco, for example, are where DH is going. But while I completely support them and think they’re doing good, important work, I feel a great lack of confidence that I can participate in any meaningful way in those conversations, both because of the professional baggage I bring with me and because they’re doing a different kind of DH. I don’t really see a category for the kinds of things I write about on DHThis or DHNow, for example.
If you want to be part of a community that HELPS DEFINE #digitalhumanities please join and promote #DHThis today! http://t.co/VTWjtGQbgr
— Adeline Koh (@adelinekoh) September 10, 2013
This is great stuff, but it’s also not going to be a venue for me wittering on about Digital Classics or text encoding. It could be my impostor syndrome kicking in, but I really doubt they’re interested.
It does seem like a side-effect of the shift toward a more theoretical DH is an environment less welcoming to participation by “staff”. It’s paradoxical that the opening up of DH also comes with a reversion to the old academic hierarchies. I’m constantly amazed at how resilient human insitutions are.
If Digital Humanities isn’t really what I do, and if Programmer comes with a load of toxic slime attached to it, perhaps “Senior” is all I have left. Of course, in programmer terms, “senior” doesn’t really mean “has many years of experience”, it’s code for “actually knows how to program”. You see ads for senior programmers with 2-3 years of experience all the time. By that standard, I’m not Senior, I’m Ancient. Job titles are something that come attached to staff, and they are terrible, constricting things.
I don’t think that what I and many of my colleagues do has become useless, even if we no longer fit the DH label. It still seems important to do that work. Maybe we’re back to doing Humanities Computing. I do think we’re mostly better off because Digital Humanities happened, but maybe we have to say goodbye to it as it heads off to new horizons and get back to doing the hard work that needs to be done in a Humanities that’s at least more open to digital approaches than it used to be. What I’m left wondering is where the place of the developer (and, for that matter other DH collaborators) is in DH if DH is now the establishment and looks structurally pretty much like the old establishment did.
Is digital humanities development a commodity? Are DH developers interchangeable? Should we be? Programming in industry is typically regarded as a commodity. Programmers are in a weird position, both providers of indispensable value, and held at arm’s length. The problem businesses have is how to harness a resource that is essentially creative and therefore very subject to human inconsistency. It’s hard to find good programmers, and hard to filter for programming talent. Programmers get burned out, bored, pissed off, distracted. Best to keep a big pool of them and rotate them out when they become unreliable or too expensive or replace them when they leave. Comparisons to graduate students and adjunct faculty may not escape the reader, though at least programmers are usually better-compensated. Academia has a slightly different programmer problem: it’s really hard to find good DH programmers and staffing up just for a project may be completely impossible. The only solution I see is to treat it as analogous to hiring faculty: you have to identify good people and recruit them and train people you’d want to hire. You also have to give them a fair amount of autonomy—to deal with them as people rather than commodities. What you can’t count on doing is retaining them as contingent labor on soft money. But here we’re back around to the faculty/staff problem: the institutions mostly only deal with tenure-track faculty in this way. Libraries seem to be the only academic institutions capable of addressing the problem at all. But they’re also the insitutions most likely to come under financial pressure and they have other things to worry about. It’s not fair to expect them to come riding over the hill.
The ideal would situation would be if there existed positions to which experts could be recruited who had sufficient autonomy to deal with faculty on their own level (this essentially means being able to say ‘no’), who might or might not have advanced degrees, who might teach and/or publish, but wouldn’t have either as their primary focus. They might be librarians, or research faculty, or something else we haven’t named yet. All of this would cost money though. What’s the alternative? Outsourcing? Be prepared to spend all your grant money paying industry rates. Grad Students? Many are very talented and have the right skills, but will they be willing to risk sacrificing the chance of a faculty career by dedicating themselves to your project? Will your project be maintainable when they move on? Mia Ridge, in her twitter feed, reminds me that in England there exist people called “Research Software Engineers”.
Notes from #rse2013 breakout discussions appearing at https://t.co/PD0ItLBb8t - lots of resonances with #musetech #codespeak
— Mia (@mia_out) September 11, 2013
There are worse labels, but it sounds like they have exactly the same set of problems I’m talking about here.
Monday, July 15, 2013
Missing DH
I'm watching the tweets from #dh2013 starting to roll in and feeling kind of sad (and, let's be honest, left out) not to be there. Conference attendance has been hard the last few years because I didn't have any travel funding in my old job. So I've tended only to go to conferences close to home or where I could get grant funding to pay for them.
It's also quite hard sometimes to decide what conferences to go to. On a self-funded basis, I can manage about one a year. So deciding which one can be hard. I'm a technologist working in a library, on digital humanities projects, with a focus on markup technologies and on ancient studies. So my list is something like:
It's also quite hard sometimes to decide what conferences to go to. On a self-funded basis, I can manage about one a year. So deciding which one can be hard. I'm a technologist working in a library, on digital humanities projects, with a focus on markup technologies and on ancient studies. So my list is something like:
- DH
- JCDL
- One of many language-focused conferences
- The TEI annual meeting
- Balisage
I could also make a case for conferences in my home discipline, Classics, but I haven't been to the APA annual meeting in over a decade. Now that the Digital Classics Association exists, that might change.
I tend to cycle through the list above. Last year I went to the TEI meeting, the year before, I went to Clojure/conj and DH (because a grant paid). The year before that, I went to Balisage, which is an absolutely fabulous conference if you're a markup geek like me (seriously, go if you get the chance).
DH is a nice compromise though, because you get a bit of everything. It's also attended by a whole bunch of my friends, and people I'd very much like to become friends with. I didn't bother submitting a proposal for this year, because my job situation was very much up in the air at the time, and indeed, I started working at DC3 just a couple of weeks ago. DH 2013 would have been unfeasible for all kinds of reasons, but I'm still bummed out not to be there. Have a great time y'all. I'll be following from a distance.
I tend to cycle through the list above. Last year I went to the TEI meeting, the year before, I went to Clojure/conj and DH (because a grant paid). The year before that, I went to Balisage, which is an absolutely fabulous conference if you're a markup geek like me (seriously, go if you get the chance).
DH is a nice compromise though, because you get a bit of everything. It's also attended by a whole bunch of my friends, and people I'd very much like to become friends with. I didn't bother submitting a proposal for this year, because my job situation was very much up in the air at the time, and indeed, I started working at DC3 just a couple of weeks ago. DH 2013 would have been unfeasible for all kinds of reasons, but I'm still bummed out not to be there. Have a great time y'all. I'll be following from a distance.
Wednesday, February 06, 2013
First Contact
It seems like I've had many versions of this conversation in the last few months, as new projects begin to ramp up:
Client: I want to do something cool to publish my work.
Developer: OK. Tell me what you'd like to do.
Client: Um. I need you to to tell me what's possible, so I can tell you what I want.
Developer: We can do pretty much anything. I need you to tell me what you want so I can figure out how to make it.
Almost every introductory meeting with a client/customer starts out this way. There's a kind of negotiation period where we figure out how to speak each other's language, often by drawing crude pictures. We look at things and decide how to describe them in a way we both understand. We wave our hands in the air and sometimes get annoyed that the other person is being so dense.Developer: OK. Tell me what you'd like to do.
Client: Um. I need you to to tell me what's possible, so I can tell you what I want.
Developer: We can do pretty much anything. I need you to tell me what you want so I can figure out how to make it.
It's crucially important not to short-circuit this process though. You and your client likely have vastly different understandings of what can be done, how hard it is to do what needs to be done, and even whether it's worth doing. The initial negotiation sets the tone for the rest of the relationship. If you hurry through it, and let things progress while there are still major misunderstandings in the air, Bad Things will certainly happen. Like:
Client: This isn't what I wanted at all!
Developer: But I built exactly what you asked for!
Developer: But I built exactly what you asked for!
Thursday, April 26, 2012
You did _what_? Form-based XML editing
My most recent project has been building an editing system for APIS (the Advanced Papyrological Information System—I know, I know) data as part of the Papyrological Editor (PE). APIS records are now TEI files. They started out using a text-based format that was MARC-inspired (fields, not structure), but I converted them to TEI a while back to bring them in line with the other papyri.info data. HGV records (also TEI) already had an editing system in the PE, so it seemed like the task of adding an APIS editor, which would be a simpler beast, wouldn't be that hard, just a matter of extending the existing one. In fact, it was an awful struggle.
Partly this is my fault. The PE is a Rails application, running on JRuby, and my Rails knowledge was pretty rusty. I loved it when I was working on it full time a few years ago, but coming back to it now, and working on an application someone else built, I found it obtuse and mentally exhausting. I had a hard time keeping in my head the different places business logic might be found, and figuring out where to graft on the pieces of the new editor was a continual fight against coder's block. The HGV editor relies on a YAML-based mapping file that documents where the editable information in an HGV document is to be found. This mapping is used to build a data structure that is used by the View to populate an editing form, and upon form submission, the process is reversed.
It's not at all unlike what XForms does, and in fact I was repeatedly saying to myself "Why didn't they just use XForms?" I got annoyed enough that I took some time to look at what it would take to just plug XForms into the application and use that for the APIS editor. The reluctant conclusion I came to was that there just aren't any XForms frameworks out there that I could do this with. And the XForms tutorials I was looking at didn't deal with data that looked like mine at all. TEI is flexible, but not all that regular, and every example I saw dealt with very regular XML data. Moreover, the only implementation I could find that wasn't a server-side framework (and I wasn't going to install another web service just to handle one form) is XSLTForms. The latter is impressive, but relies on in-browser XSLT transforms, which is fine if you have control of the whole page, but inconvenient for me, because I've already got a framework producing the shell of my pages. I just wanted something that would plug into what I already had. A bit sadder but wiser, I decided the team who built the HGV editor had done what they had to given what they had to work with.
Then, about a month ago, I got sick. Like bedridden sick. I actually took 3 days off work, which is probably the most sick leave I've taken since my children were born. While I was lying in bed waiting for the antibiotics to kick in, I got bored and thought I'd have a crack at rewriting the APIS editor. In Javascript. There was already a perfectly good pure-XML editing view, where you can open your document, make changes, and save it back (having it validated etc. on the server), so why not build something that could load the XML into a form in the browser, and then rebuild the XML with the form's contents and post it back? Doesn't sound that hard. And so that's what I did. I should say, this seemed like a potentially very silly thing to do, adding another, non-standard, editing method that duplicates the functionality of an existing standard to a system that already has a working method. I'd spent a lot of time on figuring out how to refactor the existing editor because that seemed like the Right Thing To Do. Being sick, bored, and off the clock gave me the scope to play around a bit.
Let me talk a bit more about the constraints of the project. Data is stored in XML files in a Git repository. This means that not only do I want my edits to be sending back good XML, I want it to look as much like the XML I got in the first place, with the same formatting, indentation, etc., so that Git can make sensible judgements about what has actually changed. I might want some data extracted from the XML to be processed a bit before it's put into the form, and vice versa. For example, I have dates with @when or @notBefore/@notAfter attributes that have values in the form YYYY-MM-DD, but I want my form to have separate Year, Month, and Day fields. Mixed (though only lightly mixed) content is possible in some elements. I need my form to be able to insert elements that may not be there at all in the source. I need it to deal with repeating data. I need it to deal with structured data (i.e. an XML fragment containing several pieces of data should be treated as a unit). And of course, it needs to be able to put data into the XML document in such a way that it will validate, so the order of inserted elements matters. Moreover, I need to build the form the way the framework expects it to be built, as a Rails View.
So the tool needs to know about an instance document:
Partly this is my fault. The PE is a Rails application, running on JRuby, and my Rails knowledge was pretty rusty. I loved it when I was working on it full time a few years ago, but coming back to it now, and working on an application someone else built, I found it obtuse and mentally exhausting. I had a hard time keeping in my head the different places business logic might be found, and figuring out where to graft on the pieces of the new editor was a continual fight against coder's block. The HGV editor relies on a YAML-based mapping file that documents where the editable information in an HGV document is to be found. This mapping is used to build a data structure that is used by the View to populate an editing form, and upon form submission, the process is reversed.
It's not at all unlike what XForms does, and in fact I was repeatedly saying to myself "Why didn't they just use XForms?" I got annoyed enough that I took some time to look at what it would take to just plug XForms into the application and use that for the APIS editor. The reluctant conclusion I came to was that there just aren't any XForms frameworks out there that I could do this with. And the XForms tutorials I was looking at didn't deal with data that looked like mine at all. TEI is flexible, but not all that regular, and every example I saw dealt with very regular XML data. Moreover, the only implementation I could find that wasn't a server-side framework (and I wasn't going to install another web service just to handle one form) is XSLTForms. The latter is impressive, but relies on in-browser XSLT transforms, which is fine if you have control of the whole page, but inconvenient for me, because I've already got a framework producing the shell of my pages. I just wanted something that would plug into what I already had. A bit sadder but wiser, I decided the team who built the HGV editor had done what they had to given what they had to work with.
Then, about a month ago, I got sick. Like bedridden sick. I actually took 3 days off work, which is probably the most sick leave I've taken since my children were born. While I was lying in bed waiting for the antibiotics to kick in, I got bored and thought I'd have a crack at rewriting the APIS editor. In Javascript. There was already a perfectly good pure-XML editing view, where you can open your document, make changes, and save it back (having it validated etc. on the server), so why not build something that could load the XML into a form in the browser, and then rebuild the XML with the form's contents and post it back? Doesn't sound that hard. And so that's what I did. I should say, this seemed like a potentially very silly thing to do, adding another, non-standard, editing method that duplicates the functionality of an existing standard to a system that already has a working method. I'd spent a lot of time on figuring out how to refactor the existing editor because that seemed like the Right Thing To Do. Being sick, bored, and off the clock gave me the scope to play around a bit.
Let me talk a bit more about the constraints of the project. Data is stored in XML files in a Git repository. This means that not only do I want my edits to be sending back good XML, I want it to look as much like the XML I got in the first place, with the same formatting, indentation, etc., so that Git can make sensible judgements about what has actually changed. I might want some data extracted from the XML to be processed a bit before it's put into the form, and vice versa. For example, I have dates with @when or @notBefore/@notAfter attributes that have values in the form YYYY-MM-DD, but I want my form to have separate Year, Month, and Day fields. Mixed (though only lightly mixed) content is possible in some elements. I need my form to be able to insert elements that may not be there at all in the source. I need it to deal with repeating data. I need it to deal with structured data (i.e. an XML fragment containing several pieces of data should be treated as a unit). And of course, it needs to be able to put data into the XML document in such a way that it will validate, so the order of inserted elements matters. Moreover, I need to build the form the way the framework expects it to be built, as a Rails View.
So the tool needs to know about an instance document:
- how to get data out of the XML, maybe running it through a conversion function on the way out
- how to map that data to one or a group of form elements, so there needs to be a naming convention
- how to deal with repeating elements or groups of elements
- how to structure the data coming out of the form, possibly running it through a function, and being able to deal with optional sub-structures
- how to put the form data into the correct place in the XML, so some knowledge of the content model is necessary
- how to add missing ancestor elements (maybe with attributes) for new form data
Basically, it needs to be able to deal with XML as it occurs in the wild: nasty, brutish, and (one hopes) short.
Form-based XML editing is one of those things that sounds fairly easy, but is in fact fraught with complications. It's easy to get data out of XML (XPath!), and it's easy to manipulate an XML DOM, removing and adding elements, attributes, and text nodes. But it's actually quite hard to get everything right, and to make the XML's formatting stay consistent. In my next post, I'll talk about how I did it.
Tuesday, March 20, 2012
How to Apologize
The latest regrettable spasm of sexism in the programming world played out this afternoon, as a company called Sqoot's announcement of a hackathon caused said event to implode before it ever began by including the infuriating and insensitive line under "perks" [Update: just to be clear, in the context of the original page, it was clear that the presence of women serving beer was one of the perks for attendees]:
So what are the elements of a good apology?
Women: Need another beer? Let one of our friendly (female) event staff get that for you.Gag. Sqoot fairly quickly realized they had walked into a buzzsaw, as lots of people called them on it, and their sponsors started pulling their support. It's rather nice to see that kind of quick, public reaction. Cloudmine's blog post about it particularly impressed me. Squoot issued an apology fairly swiftly, which I quote below:
Sqoot is hosting an API Jam in Boston at the end of March. One of the perks we (not our sponsors) listed on the event page was:This didn't do much for a lot of people, but it got me thinking about apologies in tech in general, since they are actually crucial moments in the interaction between you and your customers/audience. When I worked at Lulu, Bob Young used to say that whenever you screw up, it's actually a tremendous opportunity to win a customer's loyalty by making it right. This applies both to small screwups (a customer's order never made it) and large ones (you did something that made lots of people mad). It strikes me that in this day and age, when the "non-apology" has become so frequent, people may actually not realize when it isn't appropriate to use conditional or evasive language in apologies. It's one thing if you're worried about being sued and can't admit culpability, or if you're someone like Rush Limbaugh, who's presumably concerned about appearing to back down in front of his audience. But if you're actually intent on repairing the damage done to your relationship with your customer or your audience, you need to be able to apologize properly.
“Women: Need another beer? Let one of our friendly (female) event staff get that for you.”
While we thought this was a fun, harmless comment poking fun at the fact that hack-a-thons are typically male-dominated, others were offended. That was not our intention and thus we changed it.
We’re really sorry,
Avand & Mo
So what are the elements of a good apology?
- I hear you.
- I am truly sorry.
- (semi-optional, depending on what happened) This is what went wrong.
- I am doing x
to make sure this doesn't happen again and y to make it right with you. - Thank you. I appreciate the feedback.
#1 is crucial. The person or group you're addressing has to know that you've heard their complaint and understand it. Apologies that lack this element sound cold and disconnected. And this is the main problem with Sqoot's "others were offended." They aren't speaking to the people they offended. This is just guaranteed to further piss people off.
#2 should be unconditional. Not "I'm sorry if you were offended." Indeed, if you find yourself pushing the focus onto the people whom you pissed off at all, you may be sliding into non-apology territory. This isn't about them—they're mad because you made them mad. Note that a good apology is not defensive, and does not attempt to shift the blame, even if that blame belongs to an employee whom you've just fired. If you did that, it's part of #4, the "how I'm fixing it" part, not the "I'm sorry" part. Don't try to save face in a genuine apology. Indicating that you meant no harm is fine, but if you're apologizing, it means you caused harm regardless of your intent.
#3 is a bit more tricky. People want to know how this could have happened, but it doesn't do to dwell on it too much, and this is another mistake Sqoot makes. They probably shouldn't quote the line that made everyone mad (it will make the readers mad all over again). It would have been enough to say they put something stupid and sexist into an event page which they now regret. On the other hand, you do have to acknowledge what happened and not look like you're trying to dodge it. So don't go into excruciating detail about what went wrong with a customer's order, for example. "I'm afraid you found a bug in our shopping cart" is probably enough detail. Sqoot's apology does this really badly: they explain exactly what they did, how it happened (we thought it was funny, because we're aware that these things are mostly male), and then contrast the "others" (who lack their sense of humor) who were offended. Explaining how you messed up does not mean defending yourself, and defending yourself in an apology must be handled delicately, or you look like an ass.
#4 Fix it, if you can. "We're refunding your order immediately and giving you a coupon", "I shall be entering rehab tomorrow morning", "We're donating $$ to x charity".
#5 Reconnect. When you screw up, people are paying very close attention to you, and it's an opportunity to show that you're a stand-up company/organization/person. You stand to win greater loyalty and affection by handling the problem effectively. The people who are complaining (assuming they are correct, of course) are helping you by showing you where you're wrong, or at least showing you a different perspective. Squoot "signing" their apology is actually good, in this case, because it indicates the founders (I presume that's who they are) are taking responsibility. It's too bad they flubbed the middle bit.
Sunday, March 04, 2012
A spot of mansplaining
This is bit of rambling, responding to Bethany Nowviskie's terrific "Don't circle the wagons", itself a response to Miriam Posner's "Some things to think about before you exhort everyone to code".
I'm a middle-aged, white, male programmer, so that's where I'm coming from. I can't help any of that, but doubtless it colors my perspective.
First, I have to say that the idea of coding being associated with prestige (as it seems now to be in DH) is rather foreign to my experience, but the rise of the brogrammer is probably a sign that in general it's not such a marginal activity anymore. These guys would probably have gone and gotten MBAs instead in years past.
DH is slightly uncomfortable territory for programmers, as I've written in the past, at least it is for people like me who mostly program rather than academics who write code to accomplish their ends. I speak in generalities, and there are good local exceptions, but we don't get adequate (or often any) professional development funding, we don't get research time, we don't get credit for academic stuff we may do (like writing papers, presenting at conferences, etc.), we don't get to lead projects, and our jobs are very often contingent on funding. All this in exchange for about a 30% pay cut over what we could be earning in industry. There are compensations of course: incredibly interesting work, really great people to work with, and often more flexible working conditions. That's worth putting up with a lot. I have a wife and young kids, and I'm rather fond of them, so being able to work from home and having decent working hours and vacation time is a major bonus for me.
None of that in any way accounts for the gender imbalance that Miriam is highlighting, though it does perhaps work as a general disincentive (in academia) to learn to code too well. I'd also say that there is nothing that can make you feel abysmally stupid quite like the discipline of programming. Errors as small as a single character (added or omitted) can make a program fail in any number of weird ways. I am frequently faced with problems that I don't know ahead of time I'll be able to solve. Ostensibly hard problems may be dead simple to fix, while simple tasks may end up taking days. It keeps you humble. But I would say that if you're the lone woman sitting in a class/lecture/lab, and you're feeling lost, you're not the only one, and it has nothing at all to do with your gender.
As Bethany cautions, please, please don't circle the wagons. It's my contention that most of the offensive things about programmer culture are not intentional nor deeply ingrained but are actually artifacts of the gender/race imbalance.
[As an aside, I was interested in Miriam's remarks about codeacademy. I started working through it with my daughter a couple of weeks ago, and she was finding it incredibly frustrating. It does not fit her learning style at all. She, like me, needs to know why she has to type this thing. She finds being told to just type var myName="Grace" without any context stupid. In the end we gave up and started learning how to build web pages, and I'll reintroduce Javascript in that context.]
Programmer culture is exclusionary though. Undergraduate CS programs have "weed out" courses. I've actually taken a couple of these, and the first one did weed me out—it managed to be hard and extremely boring at the same time. I only came back to it years later. This gets at an aspect of programmer culture though, a sort of "are you good enough?" ethic. It's not without foundation—a lot of people who self-identify as programmers can't program—but it also means that when you start to work with a new group, there's often a kind of ritual pissing contest where you have to prove your worth before you're treated as an equal. This kind of thing is irritating enough on it's own, and it's easy to imagine it taking on sexist or racist overtones.
Programming also tends to squeeze out older folks. Actual age discrimination does happen, but it's also because staying current means almost totally rebooting your skillset every few years. The Pragmatic Programmer book recommends learning a new language every year, and this is crucial advice (my own record is more like one every 18 months or so, but that's been enough so far). If you let yourself get comfortable and coast, or go into management, your skills are going to be close to worthless in about 5 years. And, while your experience definitely gives you an edge, you're not guaranteed to have the best solution to any given problem. The 22-year-old who read something on Hacker News last night might have found an answer that totally blows your received wisdom out of the water.
[As another aside, the speed at which skills go stale means that any organization that doesn't invest in professional development for their programmers is being seriously stupid. Or they expect their devs to leave and be replaced every few years.]
The upshot is that the population of programmers not only skews male, it skews young. Put a bunch of young men together, particularly in small groups that are under a lot of pressure (in a startup, for example), and you get the sorts of tribal behaviors that make women and anyone over 35 uncomfortable. There's not just misogyny, there's hostility towards people who might want to have a life outside of work (e.g. people who have spouses and kids and like spending time with them). And this is both a cause of sexual/racial/age imbalance and a result. It's a self-reinforcing cycle.
But there isn't really one monolithic "coder culture", there are lots of them. Every company and institution has its own culture. Teams have cultures. Basically, any grouping of human beings is going to develop its own set of values and ways of doing things. It's what people do naturally. The leaders of these groups have a lot to do with how those cultures develop, but they aren't necessarily in any position to remedy imbalances.
Once you're in a position to hire people, you realize that hiring good developers is hard. In any pool of applicants, you're going to have a bunch of totally unsuitable people, a few maybes, and if you're lucky, one or two gems (or people you think might become a gem with a little polishing). Are any of these going to be women? Not unless you're really lucky, because the weeding out has already done its work. So once you're in a position to decide who gets hired, it's too late to redress any imbalance. The imbalance is not because leaders don't want to hire women, it's already there.
The only answer I can see is to get a lot more women into programming. If the CS curricula can't do it, maybe new modes like DH can. From what I've seen the gender balance in DH, while still not great, is a lot less ruinous than in programming in general, and a CS degree is far from the only road into a programming career (I don't have one). I think the cycle can be broken. I don't think there's a lot of deeply ingrained misogyny or racism in coding culture. Rather, it's a boys club because it happens to be mostly boys. If there were more women it would adjust. And I don't think that (mostly) it would put up much resistance to an influx of women. So circling the wagons is the exact opposite of what needs to be done.
I'm a middle-aged, white, male programmer, so that's where I'm coming from. I can't help any of that, but doubtless it colors my perspective.
First, I have to say that the idea of coding being associated with prestige (as it seems now to be in DH) is rather foreign to my experience, but the rise of the brogrammer is probably a sign that in general it's not such a marginal activity anymore. These guys would probably have gone and gotten MBAs instead in years past.
DH is slightly uncomfortable territory for programmers, as I've written in the past, at least it is for people like me who mostly program rather than academics who write code to accomplish their ends. I speak in generalities, and there are good local exceptions, but we don't get adequate (or often any) professional development funding, we don't get research time, we don't get credit for academic stuff we may do (like writing papers, presenting at conferences, etc.), we don't get to lead projects, and our jobs are very often contingent on funding. All this in exchange for about a 30% pay cut over what we could be earning in industry. There are compensations of course: incredibly interesting work, really great people to work with, and often more flexible working conditions. That's worth putting up with a lot. I have a wife and young kids, and I'm rather fond of them, so being able to work from home and having decent working hours and vacation time is a major bonus for me.
None of that in any way accounts for the gender imbalance that Miriam is highlighting, though it does perhaps work as a general disincentive (in academia) to learn to code too well. I'd also say that there is nothing that can make you feel abysmally stupid quite like the discipline of programming. Errors as small as a single character (added or omitted) can make a program fail in any number of weird ways. I am frequently faced with problems that I don't know ahead of time I'll be able to solve. Ostensibly hard problems may be dead simple to fix, while simple tasks may end up taking days. It keeps you humble. But I would say that if you're the lone woman sitting in a class/lecture/lab, and you're feeling lost, you're not the only one, and it has nothing at all to do with your gender.
As Bethany cautions, please, please don't circle the wagons. It's my contention that most of the offensive things about programmer culture are not intentional nor deeply ingrained but are actually artifacts of the gender/race imbalance.
[As an aside, I was interested in Miriam's remarks about codeacademy. I started working through it with my daughter a couple of weeks ago, and she was finding it incredibly frustrating. It does not fit her learning style at all. She, like me, needs to know why she has to type this thing. She finds being told to just type var myName="Grace" without any context stupid. In the end we gave up and started learning how to build web pages, and I'll reintroduce Javascript in that context.]
Programmer culture is exclusionary though. Undergraduate CS programs have "weed out" courses. I've actually taken a couple of these, and the first one did weed me out—it managed to be hard and extremely boring at the same time. I only came back to it years later. This gets at an aspect of programmer culture though, a sort of "are you good enough?" ethic. It's not without foundation—a lot of people who self-identify as programmers can't program—but it also means that when you start to work with a new group, there's often a kind of ritual pissing contest where you have to prove your worth before you're treated as an equal. This kind of thing is irritating enough on it's own, and it's easy to imagine it taking on sexist or racist overtones.
Programming also tends to squeeze out older folks. Actual age discrimination does happen, but it's also because staying current means almost totally rebooting your skillset every few years. The Pragmatic Programmer book recommends learning a new language every year, and this is crucial advice (my own record is more like one every 18 months or so, but that's been enough so far). If you let yourself get comfortable and coast, or go into management, your skills are going to be close to worthless in about 5 years. And, while your experience definitely gives you an edge, you're not guaranteed to have the best solution to any given problem. The 22-year-old who read something on Hacker News last night might have found an answer that totally blows your received wisdom out of the water.
[As another aside, the speed at which skills go stale means that any organization that doesn't invest in professional development for their programmers is being seriously stupid. Or they expect their devs to leave and be replaced every few years.]
The upshot is that the population of programmers not only skews male, it skews young. Put a bunch of young men together, particularly in small groups that are under a lot of pressure (in a startup, for example), and you get the sorts of tribal behaviors that make women and anyone over 35 uncomfortable. There's not just misogyny, there's hostility towards people who might want to have a life outside of work (e.g. people who have spouses and kids and like spending time with them). And this is both a cause of sexual/racial/age imbalance and a result. It's a self-reinforcing cycle.
But there isn't really one monolithic "coder culture", there are lots of them. Every company and institution has its own culture. Teams have cultures. Basically, any grouping of human beings is going to develop its own set of values and ways of doing things. It's what people do naturally. The leaders of these groups have a lot to do with how those cultures develop, but they aren't necessarily in any position to remedy imbalances.
Once you're in a position to hire people, you realize that hiring good developers is hard. In any pool of applicants, you're going to have a bunch of totally unsuitable people, a few maybes, and if you're lucky, one or two gems (or people you think might become a gem with a little polishing). Are any of these going to be women? Not unless you're really lucky, because the weeding out has already done its work. So once you're in a position to decide who gets hired, it's too late to redress any imbalance. The imbalance is not because leaders don't want to hire women, it's already there.
The only answer I can see is to get a lot more women into programming. If the CS curricula can't do it, maybe new modes like DH can. From what I've seen the gender balance in DH, while still not great, is a lot less ruinous than in programming in general, and a CS degree is far from the only road into a programming career (I don't have one). I think the cycle can be broken. I don't think there's a lot of deeply ingrained misogyny or racism in coding culture. Rather, it's a boys club because it happens to be mostly boys. If there were more women it would adjust. And I don't think that (mostly) it would put up much resistance to an influx of women. So circling the wagons is the exact opposite of what needs to be done.
Monday, November 14, 2011
TEI in other formats; part the second: Theory
In my first post on this subject, I poked a bit at how one might represent TEI in HTML without discarding the text model from the TEI document. Now I want to talk a bit more about that model, and the theory behind it. I may at the end say irritable things about Theory as well, if you can stand it until the end. I humbly beg the reader's pardon.
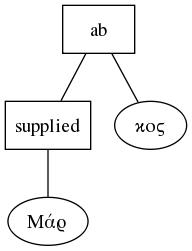
Let's look at the same document I talked about last time: http://papyri.info/ddbdp/p.ryl;2;74/source (see also http://papyri.info/ddbdp/p.ryl;2;74/). We can visualize the document structure using Graphviz and a spot of XSLT (click for high-res):

This may all seem like a numbing level of detail, but it is on these details that theories of text are tested. The text model here cares about editorial observations on and interventions in the text, and those are what it attempts to capture. It cares much less about the structure of the text itself—note that the text is contained in a tei:ab, an element designed for delineating a block of text without saying anything about its nature as a block (unlike tei:p, for example). Visible features like columns, or text continued on multiple papyri, or multiple texts on the same papyrus would be marked by tei:divs. This is in keeping with papyrology's focus on the materiality of the text. What the editor sees, and what they make of it is more important than the construction of a coherent narrative from the text—something that is often impossible in any case. Making that set of tasks as easy as possible is therefore the focus of the text model we use.
What I'm trying to get at here is that there is Theory at work here (a host of theories in fact), having to do with a way to model texts, and that that set of theories are mapped onto data structures (TEI, XML, the tree) using a set of conventions, and taking advantage of some of the strengths of the data structures available. Those data structures have weaknesses too, and where we hit those, we have to make choices about how to serve our theories best with the tools we have. There is no end of work to be done at this level, of joining theory to practice, and a great deal of that work involves hacking, experimenting with code and data. It is from this realization, I think, that the "more hack, less yack" ethic of THATCamp emerged. And it is at this level, this intersection, this interface, that scholar-programmer types (like me) spend a lot of our time. And we do get a bit impatient with people who don't, or can't, or won't engage at the same level, especially if they then produce critiques of what we're doing.
As it happens, I do think that DH tends to be under-theorized, but by that I don't mean it needs more Foucault. Because it is largely project-driven, and the people who are able to reason about the lower-level modeling and interface questions are mostly paid only to get code into production, important decisions and theories are left implicit in code and in the shapes of the data, and aren't brought out into the light of day and yacked about as they should be.
Let's look at the same document I talked about last time: http://papyri.info/ddbdp/p.ryl;2;74/source (see also http://papyri.info/ddbdp/p.ryl;2;74/). We can visualize the document structure using Graphviz and a spot of XSLT (click for high-res):
 |
| tree structure of a TEI document |
It's a fairly flat tree. As an XML document, it has to be a tree, of course, and TEI leverages this built-in "tree-ness" to express concepts like "this text is part of a paragraph" (i.e. it has a tei:p element as its ancestor). In line 1, for example, we find
<supplied reason="lost">Μάρ</supplied>κοςmeaning the first three letters of the name Markos have been lost due to damage suffered by the papyrus the text was written on, and the editor of the text has supplied them. The fact that the letters "Μάρ" are contained by the supplied element, or, more properly that the text node containing those letters is a child of the supplied element, means that those letters have been supplied. In other words, the parent-child relationship is given additional semantics by TEI. We already have some problems here: the child of supplied is itself part of a word, "Markos", and that word is broken up by the supplied element. Only the fact that no white space intervenes between the end of the supplied element and the following text lets us know that this is a word. It's even worse if you look at the tree version, which is, incidentally, how the document will be interpreted by a computer after it has been parsed:
There's no obvious connection here between the first and second halves of the name. And in fact, if we hadn't taken steps to prevent it, any program the processed the document might reformat it so that "Mar" and "kos" were no longer connected. We could solve this problem by adding more elements. As the joke goes, "XML is like violence. If it isn't working, you're not using it enough." We could explicitly mark all the words, using a "w" element, thus:
<w><supplied reason="lost">Μάρ</supplied>κος</w>or
which would solve any potential problems with words getting split up, because we could always fix the problem—we would know what all the words are. We could even attach useful metadata, like the lemma (the dictionary headword) of the word in question. We don't do this for a couple of reasons. First, because we don't need to. We can work around the splitting-up of words by markup. Second, because it complicates the document and makes it harder for human editors to deal with, and third, because it introduces new chances for overlap. Overlap is the Enemy, as far as XML is concerned. The more containers you have, the greater the chances one container will need to start outside another, but finish inside (or vice versa). Consider that there's no reason at all a region of supplied text shouldn't start in the middle of one word and end in the middle of another. Look at lines 5-6 for example:
... οὐ̣[χ ἱκανὸν εἶ-]A supplied section begins in the middle of the third word from the end of line five, and continues for the rest of the line. The last word is itself broken and continues on the following line, the beginning of which is also supplied, that section ending in the middle of the second word on line six. This is a mess that would only be compounded if we wanted to mark off words.
[ναι εἰ]ς
This may all seem like a numbing level of detail, but it is on these details that theories of text are tested. The text model here cares about editorial observations on and interventions in the text, and those are what it attempts to capture. It cares much less about the structure of the text itself—note that the text is contained in a tei:ab, an element designed for delineating a block of text without saying anything about its nature as a block (unlike tei:p, for example). Visible features like columns, or text continued on multiple papyri, or multiple texts on the same papyrus would be marked by tei:divs. This is in keeping with papyrology's focus on the materiality of the text. What the editor sees, and what they make of it is more important than the construction of a coherent narrative from the text—something that is often impossible in any case. Making that set of tasks as easy as possible is therefore the focus of the text model we use.
What I'm trying to get at here is that there is Theory at work here (a host of theories in fact), having to do with a way to model texts, and that that set of theories are mapped onto data structures (TEI, XML, the tree) using a set of conventions, and taking advantage of some of the strengths of the data structures available. Those data structures have weaknesses too, and where we hit those, we have to make choices about how to serve our theories best with the tools we have. There is no end of work to be done at this level, of joining theory to practice, and a great deal of that work involves hacking, experimenting with code and data. It is from this realization, I think, that the "more hack, less yack" ethic of THATCamp emerged. And it is at this level, this intersection, this interface, that scholar-programmer types (like me) spend a lot of our time. And we do get a bit impatient with people who don't, or can't, or won't engage at the same level, especially if they then produce critiques of what we're doing.
As it happens, I do think that DH tends to be under-theorized, but by that I don't mean it needs more Foucault. Because it is largely project-driven, and the people who are able to reason about the lower-level modeling and interface questions are mostly paid only to get code into production, important decisions and theories are left implicit in code and in the shapes of the data, and aren't brought out into the light of day and yacked about as they should be.
Thursday, November 10, 2011
TEI in other formats; part the first: HTML
There has been a fair amount of discussion of late about TEI either having a standard HTML5 representation or even moving entirely to an HTML5 format. I want to do a little thinking "out loud" about how that might work.
Let's start with a fairly standard EpiDoc document (EpiDoc being a set of guidelines for using TEI to mark up ancient documents). http://papyri.info/ddbdp/p.ryl;2;74/source (see http://papyri.info/ddbdp/p.ryl;2;74/ for an HTML version with more info) is a fairly typical example of EpiDoc used to mark up a papyrus document. The document structure is fairly flat, but with a number of editorial interventions, all marked up. Line 12, below, shows supplied, unclear, and gap tags
<lb n="12"/><gap reason="lost" quantity="16" unit="character"/> <supplied reason="lost"> Π</supplied><unclear>ε</unclear>ρὶ Θή<supplied reason="lost">βας καὶ Ἑ</supplied><unclear>ρ</unclear>μωνθ<supplied reason="lost">ίτ </supplied><gap reason="lost" extent="unknown" unit="character"/>
So how might we take this line and translate it to HTML? First, we have an <lb> tag, which at first glance would seem to map quite readily onto the HTML <br> tag, but if we look at the TEI Guidelines page for lb (http://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lb.html), we see a large number of possible attributes that don't necessarily convert well. In practice, all I usually see on a line break tag in TEI is an @n and maybe an @xml:id attribute. HTML doesn't really have a general-purpose attribute like @n, but @class or @title might serve. On <lb>, @n is often used to provide line numbers, so @title seems logical.
Now <gap reason="lost" quantity="16" unit="character"/> is a bit more of a puzzler. First, HTML's semantics don't extend at all to the recording of attributes of a text being transcribed, so nothing like the gap element exists. We'll have to use a general-purpose inline element (span seems obvious) and figure out how to represent the attribute values. TEI has no lack of attributes, and these don't naturally map to HTML at all in most cases. If we're going to keep TEI's attributes, we'll have to represent them as child elements. We'll want to identify both the original TEI element and wrap its attributes and maybe its content too, so let's assume we'll use the @class attribute with a couple of fake "namespaces", "teie-" for TEI element names, "teia-" for attribute names, and "teig-" to identify attributes and wrap element contents (the latter might be overkill, but seems sensible as a way to control whitespace). We can assume a stylesheet with a span.teig-attribute selector that sets display:none.
<span class="tei-gap">
<span class="teig-attribute teia-reason">lost</span>
<span class="teig-attribute teia-quantity">16</span>
<span class="teig-attribute teia-unit">character</span>
</span>
Like HTML, TEI has three structural models for elements: block, inline, and milestone. Block elements assume a "block" of text, that is, they create a visually distinct chunk of text. Divs, paragraphs, tables, and similar elements are block level. Inline elements contain content, but don't create a separate block. Examples are span in HTML, or hi in TEI. Milestones are empty elements like lb or br. TEI has several of these, and HTML, which has "generic" elements of the block and inline varieties (div and span) lacks a generic empty element. Hence the need to represent tei:gap as a span.
tei:supplied is clearly an inline element, and we can do something similar to the example above, using span:
<span class="tei-supplied">
<span class="teig-attribute teia-reason">lost</span>
<span class="teig-content">Π</span>
</span>
and likewise with unclear:
<span class="tei-unclear">
<span class="teig-content">ε</span>
</span>
Now, doing this using generic HTML elements and styling/hiding them with CSS could be considered bad behavior. It's certainly frowned upon in the CSS 2.1 spec (see the note at http://www.w3.org/TR/CSS2/selector.html#class-html). I don't honestly see another way to do it though, because, although RDFa has been suggested as a vehicle for porting TEI to HTML, there is no ontology for TEI, so no good way to say "HTML element p is the same as TEI element p, here". Even granting the possibility of saying that, it doesn't help with the attribute problem. And we're still left with the problem of presentation: what will my HTML look like in a browser? It must be said that my messing about above won't produce anything like the desired effect, which for line 12 is something like:
I suspect I'm missing the point here, and that what the proponents of TEI in HTML are really after is a radically curtailed (or re-thought) version of TEI that does map more comfortably to HTML. The somewhat Baroque complexity of TEI leads the casual observer to wish for something simpler immediately, and can provoke occasional dismay even in experienced users. I certainly sympathize with the wish for a simpler architecture, but text modeling is a complex problem, and simple solutions to complex problems are hard to engineer.
Let's start with a fairly standard EpiDoc document (EpiDoc being a set of guidelines for using TEI to mark up ancient documents). http://papyri.info/ddbdp/p.ryl;2;74/source (see http://papyri.info/ddbdp/p.ryl;2;74/ for an HTML version with more info) is a fairly typical example of EpiDoc used to mark up a papyrus document. The document structure is fairly flat, but with a number of editorial interventions, all marked up. Line 12, below, shows supplied, unclear, and gap tags
<lb n="12"/><gap reason="lost" quantity="16" unit="character"/> <supplied reason="lost"> Π</supplied><unclear>ε</unclear>ρὶ Θή<supplied reason="lost">βας καὶ Ἑ</supplied><unclear>ρ</unclear>μωνθ<supplied reason="lost">ίτ </supplied><gap reason="lost" extent="unknown" unit="character"/>
So how might we take this line and translate it to HTML? First, we have an <lb> tag, which at first glance would seem to map quite readily onto the HTML <br> tag, but if we look at the TEI Guidelines page for lb (http://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lb.html), we see a large number of possible attributes that don't necessarily convert well. In practice, all I usually see on a line break tag in TEI is an @n and maybe an @xml:id attribute. HTML doesn't really have a general-purpose attribute like @n, but @class or @title might serve. On <lb>, @n is often used to provide line numbers, so @title seems logical.
Now <gap reason="lost" quantity="16" unit="character"/> is a bit more of a puzzler. First, HTML's semantics don't extend at all to the recording of attributes of a text being transcribed, so nothing like the gap element exists. We'll have to use a general-purpose inline element (span seems obvious) and figure out how to represent the attribute values. TEI has no lack of attributes, and these don't naturally map to HTML at all in most cases. If we're going to keep TEI's attributes, we'll have to represent them as child elements. We'll want to identify both the original TEI element and wrap its attributes and maybe its content too, so let's assume we'll use the @class attribute with a couple of fake "namespaces", "teie-" for TEI element names, "teia-" for attribute names, and "teig-" to identify attributes and wrap element contents (the latter might be overkill, but seems sensible as a way to control whitespace). We can assume a stylesheet with a span.teig-attribute selector that sets display:none.
<span class="tei-gap">
<span class="teig-attribute teia-reason">lost</span>
<span class="teig-attribute teia-quantity">16</span>
<span class="teig-attribute teia-unit">character</span>
</span>
Like HTML, TEI has three structural models for elements: block, inline, and milestone. Block elements assume a "block" of text, that is, they create a visually distinct chunk of text. Divs, paragraphs, tables, and similar elements are block level. Inline elements contain content, but don't create a separate block. Examples are span in HTML, or hi in TEI. Milestones are empty elements like lb or br. TEI has several of these, and HTML, which has "generic" elements of the block and inline varieties (div and span) lacks a generic empty element. Hence the need to represent tei:gap as a span.
tei:supplied is clearly an inline element, and we can do something similar to the example above, using span:
<span class="tei-supplied">
<span class="teig-attribute teia-reason">lost</span>
<span class="teig-content">Π</span>
</span>
and likewise with unclear:
<span class="tei-unclear">
<span class="teig-content">ε</span>
</span>
Now, doing this using generic HTML elements and styling/hiding them with CSS could be considered bad behavior. It's certainly frowned upon in the CSS 2.1 spec (see the note at http://www.w3.org/TR/CSS2/selector.html#class-html). I don't honestly see another way to do it though, because, although RDFa has been suggested as a vehicle for porting TEI to HTML, there is no ontology for TEI, so no good way to say "HTML element p is the same as TEI element p, here". Even granting the possibility of saying that, it doesn't help with the attribute problem. And we're still left with the problem of presentation: what will my HTML look like in a browser? It must be said that my messing about above won't produce anything like the desired effect, which for line 12 is something like:
[- ca.16 - Π]ε̣ρὶ Θή[βας καὶ Ἑ]ρ̣μωνθ[ίτ -ca.?- ]I could certainly make it so, probably with a combination of CSS and JavaScript, but what have I gained by doing so? I'll have traded one paradigm, XML + XSLT, for another, HTML + CSS + JavaScript. I'll have lost the ability to validate my markup, though I'll still be able to transform it to other formats. I should be able to round-trip it to TEI and back, so perhaps I could solve the validation problem that way. But is anything about this better than TEI XML? I don't think so…
I suspect I'm missing the point here, and that what the proponents of TEI in HTML are really after is a radically curtailed (or re-thought) version of TEI that does map more comfortably to HTML. The somewhat Baroque complexity of TEI leads the casual observer to wish for something simpler immediately, and can provoke occasional dismay even in experienced users. I certainly sympathize with the wish for a simpler architecture, but text modeling is a complex problem, and simple solutions to complex problems are hard to engineer.
Tuesday, June 28, 2011
Humanities Data Curation
Last Thursday, I attended the excellent Humanities Data Curation Summit, organized by Allen Renear, Trevor Muñoz, Katherine L. Walter, and Julia Flanders. I'm still processing the day, which included a breakout session with Allen, Elli Mylonas, and Michael Sperberg-McQueen, who are some of my favorite people in DH.
What I started thinking about today was that we'd skipped definitions at the beginning—there was a joke that Allen, as a philosopher, could have spent all day on that task. But in doing so, we elided the question of what is data in the humanities, and what is different about it from science or social science data.
Humanities data are not usually static, collected data like instrument readings or survey results. They are things like marked up texts, uncorrected OCR, images in need of annotation, etc. Humanities datasets can almost always be improved upon. "Curation" for them is not simply preservation, access, and forward migration. It means enabling interested communities to work with the data and make it better. Community interaction needs to be factored into the data's curation lifecycle.
I feel a blog post coming on about how the Integrating Digital Papyrology / papyri.info project does this...
What I started thinking about today was that we'd skipped definitions at the beginning—there was a joke that Allen, as a philosopher, could have spent all day on that task. But in doing so, we elided the question of what is data in the humanities, and what is different about it from science or social science data.
Humanities data are not usually static, collected data like instrument readings or survey results. They are things like marked up texts, uncorrected OCR, images in need of annotation, etc. Humanities datasets can almost always be improved upon. "Curation" for them is not simply preservation, access, and forward migration. It means enabling interested communities to work with the data and make it better. Community interaction needs to be factored into the data's curation lifecycle.
I feel a blog post coming on about how the Integrating Digital Papyrology / papyri.info project does this...
Thursday, January 20, 2011
Interfaces and Models
In my last post, I argued that TEI is a text modelling language, and in the prior post, I discussed a frequently-expressed request for TEI editors that hide the tags. Here, I'm going to assert that your editing interface (implicitly) expresses a model too, and because it does, generic, tag-hiding editors are a losing proposition.
Everything to do with human-computer interfaces uses models, abstractions, and metaphors. Your computer "desktop" is a metaphor that treats the primary, default interface like the surface of a desk, where you can leave stuff laying around that you want to have close at hand. "Folders" are like physical file folders. Word processors make it look like you're editing a printed page; HTML editors can make it look as though you're directly editing the page as it appears in a browser. These metaphors work by projecting an image that looks like something you (probably) already have a mental model of. The underlying model used by the program or operating system is something else again. Folders don't actually represent any physical containment on the system's local storage, for example. The WYSIWYG text you edit might be a stream of text and formatting instructions, or a Document Object Model (DOM) consisting of Nodes that model HTML elements and text.
If you're lucky, there isn't a big mismatch between your mental model and the computer's. But sometimes there is: we've all seen weirdly mis-formatted documents, where instead of using a header style for header text, the writer just made it bold, with a bigger font, and maybe put a couple of newlines after it. Maybe you've done this yourself, when you couldn't figure out the "right" way to do it. This kind of thing only bites you, after all, when you want to do something like change the font for all headers in a document.
And how do we cope if there's a mismatch between the human interface and the underlying model? If the interface is much simpler than the model, then you will only be able to create simple instances with it; you won't be able to use the model to its full capabilities. We see this with word processor-to-TEI converters, for example. The word processor can do structural markup, like headers and paragraphs, but it can't so easily do more complex markup. You could, in theory, have a tagless TEI editor capable of expressing the full range of TEI, but it would have to be as complex as the TEI is. You could hide the angle brackets, but you'd have to replace them with something else.
Because TEI is a language for producing models of texts, it is probably impossible to build a generic tagless TEI editor. In order for the metaphor to work, there must be a mapping from each TEI structure to a visual feature in the editor. But in TEI, there are always multiple ways of expressing the same information. The one you choose is dictated by your goals, by what you want to model, and by what you'll want the model to do. There's nothing to map to on the TEI side until you've chosen your model. Thus, while it's perfectly possible (and is useful,* and has been done, repeatedly) to come up with a "tagless" interface that works well for a particular model of text, I will assert that developing a generic TEI editor that hides the markup would be hard task.
This doesn't mean you couldn't build a tool to generate model-specific TEI editors, or build a highly-customizable tagless editor. But the customization will be a fairly hefty intellectual effort. And there's a potential disadvantage here too: creating such a customization implies that you know exactly how you want your model to work, and at the start of a project, you probably don't. You might find, for example, that for 1% of your texts, your initial assumptions about your text model are completely inadequate, and so it has to be refined to account for them. This sort of thing happens all the time.
My advice is to think hard before deciding to "protect" people from the markup. Text modeling is a skill that any scholar of literature could stand to learn.
UPDATE: a comment on another site by Joe Wicentowski makes me think I wasn't completely clear above. There's NOTHING wrong with building "padded cell" editors that allow users to make only limited changes to data. But you need to be clear about what you want to accomplish with them before you implement one.
*Michael C. M. Sperberg-McQueen has a nice bit on "padded cell editors" at http://www.blackmesatech.com/view/?p=11
Everything to do with human-computer interfaces uses models, abstractions, and metaphors. Your computer "desktop" is a metaphor that treats the primary, default interface like the surface of a desk, where you can leave stuff laying around that you want to have close at hand. "Folders" are like physical file folders. Word processors make it look like you're editing a printed page; HTML editors can make it look as though you're directly editing the page as it appears in a browser. These metaphors work by projecting an image that looks like something you (probably) already have a mental model of. The underlying model used by the program or operating system is something else again. Folders don't actually represent any physical containment on the system's local storage, for example. The WYSIWYG text you edit might be a stream of text and formatting instructions, or a Document Object Model (DOM) consisting of Nodes that model HTML elements and text.
If you're lucky, there isn't a big mismatch between your mental model and the computer's. But sometimes there is: we've all seen weirdly mis-formatted documents, where instead of using a header style for header text, the writer just made it bold, with a bigger font, and maybe put a couple of newlines after it. Maybe you've done this yourself, when you couldn't figure out the "right" way to do it. This kind of thing only bites you, after all, when you want to do something like change the font for all headers in a document.
And how do we cope if there's a mismatch between the human interface and the underlying model? If the interface is much simpler than the model, then you will only be able to create simple instances with it; you won't be able to use the model to its full capabilities. We see this with word processor-to-TEI converters, for example. The word processor can do structural markup, like headers and paragraphs, but it can't so easily do more complex markup. You could, in theory, have a tagless TEI editor capable of expressing the full range of TEI, but it would have to be as complex as the TEI is. You could hide the angle brackets, but you'd have to replace them with something else.
Because TEI is a language for producing models of texts, it is probably impossible to build a generic tagless TEI editor. In order for the metaphor to work, there must be a mapping from each TEI structure to a visual feature in the editor. But in TEI, there are always multiple ways of expressing the same information. The one you choose is dictated by your goals, by what you want to model, and by what you'll want the model to do. There's nothing to map to on the TEI side until you've chosen your model. Thus, while it's perfectly possible (and is useful,* and has been done, repeatedly) to come up with a "tagless" interface that works well for a particular model of text, I will assert that developing a generic TEI editor that hides the markup would be hard task.
This doesn't mean you couldn't build a tool to generate model-specific TEI editors, or build a highly-customizable tagless editor. But the customization will be a fairly hefty intellectual effort. And there's a potential disadvantage here too: creating such a customization implies that you know exactly how you want your model to work, and at the start of a project, you probably don't. You might find, for example, that for 1% of your texts, your initial assumptions about your text model are completely inadequate, and so it has to be refined to account for them. This sort of thing happens all the time.
My advice is to think hard before deciding to "protect" people from the markup. Text modeling is a skill that any scholar of literature could stand to learn.
UPDATE: a comment on another site by Joe Wicentowski makes me think I wasn't completely clear above. There's NOTHING wrong with building "padded cell" editors that allow users to make only limited changes to data. But you need to be clear about what you want to accomplish with them before you implement one.
*Michael C. M. Sperberg-McQueen has a nice bit on "padded cell editors" at http://www.blackmesatech.com/view/?p=11
Tuesday, January 11, 2011
TEI is a text modelling language
I'm teaching a TEI class this weekend, so I've been pondering it a bit. I've come to the conclusion that calling what we do with TEI "text encoding" is misleading. I think what we're really doing is text modeling.
TEI provides an XML vocabulary that lets you produce models of texts that can be used for a variety of purposes. Not a Model of Text, mind you, but models (lowercase) of texts (also lowercase).
TEI has made the (interesting, significant) decision to piggyback its semantics on the structure of XML, which is tree-based. So XML structure implies semantics for a lot of TEI. For example, paragraph text appears inside <p> tags; to mark a personal name, I surround the name with a <persname> tag, and so on. This arrangement is extremely convenient for processing purposes: it is trivial to transform the TEI <p> into an HTML <p>*, for example, or the <persname> into an HTML hyperlink, which points to more information about the person. It means, however, that TEI's modeling capabilities are to a large extent XML's own. This approach has opened TEI up to criticism. Buzetti (2002) has argued that its tree structure simply isn't expressive enough to represent the complexities of text, and Schmidt (2010) criticizes TEI for (among other problems) being a bad model of text, because it imposes editorial interpretation on the text itself.
The main disagreement I have with Schmidt's argument is the assumption that there is a text independent of the editorial apparatus. Maybe there is sometimes, but I can point at many examples where there is no text, as such, only readings. And a reading is, must be, an interpretive exercise. So I'd argue that TEI is at least honest in that it puts the editorial interventions front and center where they are obvious.
As for the argument that TEI's structure is inadequate to model certain aspects of text, I can only agree. But TEI has proved good enough to do a lot of serious scholarly work. That, and the fact that its choice of structure means it can bring powerful XML tools to bear on the problems it confronts, means that TEI represents a "worse is better" solution.† It works a lot of the time, doesn't claim to be perfect, and incrementally improves. Where TEI isn't adequate to model a text in the way you want to use it, then you either shouldn't use it, or should figure out how to extend it.
One should bear in mind that any digital representation of a text is ipso facto a model. It's impossible do anything digital without a model (whether you realize it's there or not). Even if you're just transcribing text from a printed page to a text editor you're making editorial decisions, like what character encoding to use, how to represent typographic features in that encoding, how to represent whitespace, and what to do with things you can't easily type (inline figures or symbols without a Unicode representation, for example).
So why argue that TEI is a language for modeling texts, rather than a language for "encoding" texts? The simple answer is that this is a better way of explaining what people use TEI for. TEI provides a lot of tags to choose from. No-one uses them all. Some are arguably incompatible with one another. We tag the things in a text that we care about and want to use. In other words, we build models of the source text, models that reflect what we think is going on structurally, semantically, or linguistically in the text, and/or models that we hope to exploit in some way.
For example, EpiDoc is designed to produce critical editions of inscribed or handwritten ancient texts. It is concerned with producing an edition (a reading) of the source text that records the editor's observations of and ideas about that text. It does not at this point concern itself with marking personal or geographic names in the text. An EpiDoc document is a particular model of the text that focuses on the editor's reading of that text. As a counterexample, I might want to use TEI to produce a graph of the interactions of characters in Hamlet. If I wanted to do that, I would produce a TEI document that marked people and whom they were addressing when they spoke. This would be a completely different model of the text than a critical edition of Hamlet might be. I could even try to do both at the same time, but that might be a mess—models are easier to deal with when they focus on one thing.
This way of understanding TEI makes clear a problem that arises whenever one tries to merge collections of TEI documents: that of compatibility. Just because two documents are marked up in TEI, that does not mean they are interoperable. This is because each document represents the editor's model of that text. Compatibility is certainly achievable if both documents follow the same set of conventions, but we shouldn't expect it any more than we'd expect to be able to merge any two models that follow different ground rules.
Notes
* with the caveat that the semantics of TEI <p> and HTML <p> are different, and there may be problems. TEI's <p> can contain lists, for example, whereas HTML's cannot.
Yes, I wrote a blog post with endnotes and bibliography. Sue me.
- Buzzetti D. "Digital Representation and the Text Model." New Literary History 2002; 33.1:61-88.
- Schmidt, D. "The Inadequacy of Embedded Markup for Cultural Heritage Texts." Literary and LInguistic Computing 2010; 25.3:337-356.
Thursday, January 06, 2011
I Will Never NOT EVER Type an Angle Bracket (or IWNNETAAB for short)
From time to time, I hear an argument that goes something like this: "Our users won't deal with angle brackets, therefore we can't use TEI, or if we do, it has to be hidden from them." It's an assumption I've encountered again quite recently. Since it's such a common trope, I wonder how true it is. Of course, I can't speak for anyone's user communities other than the ones I serve. And mine are perhaps not the usual run of scholars. But they haven't tended to throw their hands up in horror at the sight of angle brackets. Indeed, some of them have become quite expert at editing documents in TEI.
The problems with TEI (and XML in general) are manifold, but its shortcomings often center around its not being expressive *enough* to easily deal with certain classes of problem. And the TEI evolves. You can get involved and change it for the better.
The IWNNETAAB objection seems grounded in fear. But fear of what? As I mentioned at the start, IWNNETAAB isn't usually an expression of personal revulsion, it's not just Luddism, it's IWNNETAAB by proxy: my users/clients/stakeholders won't stand for it. Or they'll mess it up. TEI is hard. It has *hundreds* of elements. How can they/why should they learn something so complex just to be able to digitize texts?! What we want to do is simple, can't we have something simple that produces TEI in the end?
The problem with simplified editing interfaces is easy to understand: they are simple. Complexities have been removed, and along with them, the ability to express complex things. To put it another way, if you aren't dealing with the tags, you're dealing with something in which a bunch of decisions have already been made for you. My argument in the recent discussion was that in fact, these decisions tend to be extremely project-specific. You can't set it up once and expect it to work again in different circumstances; you (or someone) will have to do it over and over again. So, for a single project, the cost/benefit equation may look like it leans toward the "simpler" option. But taken over many projects, you're looking either at learning a reasonably complex thing or building a long series of tools that each produce a different version of that thing. Seen in this light, I think learning TEI makes a lot of sense. On the learning TEI side, the costs go down over time, on the GUI interface side, they keep going up.
Moreover, knowing TEI means that you (or your stakeholders) aren't shackled to an interface that imposes decisions that were made before you ever looked at the text you're encoding, instead, you are actually engaging with the text, in the form in which it will be used. You're seeing behind the curtain. I can't really fathom why that would be a bad thing.
(Inspiration for the title comes from a book my 2-year-old is very fond of)

Tuesday, December 28, 2010
DH Tea Leaves
From reading my (possibly) representative sample of DH proposals, I'd say the main theme of the conference will not be "Big Tent Digital Humanities" but "data integration". Of the 8 proposals I read, more than half of them were concerned with problems of connecting data across projects, disciplines, and different systems. My proposal was too (making 9), so perhaps I did have a representative sample.
Data integration is a meaty problem, resistant to generalized solutions. To my mind the answers, such as they are, will rely on the same set of practices that good data curation techniques use: open formats and open source code, and good documentation that covers the "why" of decisions made for projects as well as the "how." Data integration is a process that involves gaining an understanding of the sources and the semantics of their structures before you can connect them together. So, while there are tools out there that can enable successful data integration, there are (as usual) no silver bullets. Grasping the meanings and assumptions embodied in each project's data structures has to be the first step and this is only possible when those structures have been explained.
Sunday, December 05, 2010
That Bug Bit Me
"I had this problem and I fixed it" stories are boring to anyone except those intimately concerned with the problem, so I'm not going to tell that story. Instead, I'm going to talk about projects in the Digital Humanities that rely on 3rd party software, and talk about the value of expertise in programming and software architecture. From the outside, modern software development can look like building a castle out of Lego pieces: you take existing components and pop them together. Need search? Grab Apache Solr and plug it in. Need a data store? Grab a (No)SQL database and put your data in it. Need to do web development fast? Grab a framework, like Rails or Django. Doesn't sound that hard.
This is, more or less, what papyri.info looks like internally. There's a Solr install that handles search, a Mulgara triple store that keeps track of document relationships, small bits of code that handle populating the former two and displaying the web interface, and a JRuby on Rails application that provides crowdsourced editing capabilities.
Upgrading components in this architecture should range from trivially easy, to moderately complex (that's only if some interface has changed between versions, for example).
So why did I find myself sitting in a hotel lobby in Rome a few weeks ago having to roll back an to an older version of Mulgara so the editor application would work for a presentation the next day? A bunch of our queries had stopped working, meaning the editor couldn't load texts to edit. Oops.
And why did I spend the last week fighting to keep the application standing up after a new release of the editor was deployed?
The answer to both questions was that our Lego blocks didn't function the way they were supposed to. They aren't Lego blocks after all—they're complex pieces of software that may have bugs. The fact that our components are open source, and have responsive developers behind them is a help, but we can't necessarily expect those developers to jump to solve our problems. After all, the project's tests must have passed in order for the new release to be pushed, and unless there's a chorus of complaint, our problem isn't necessarily going to be high on their list of things to fix.
No, the whole point of using open source components is that you don't have to depend solely on other people to fix your problems. In the case of Mulgara, I was able to track down and fix the bug myself, with some pointers from the lead developer. The fix (or a better version of it) will go into the next release, and meantime we can use my patched version. In the case of the Rails issue, there seems to be a bug in the ActiveSupport file caching under JRuby that causes it to go nuts: the request never returns and something continually creates resources that have to be garbage collected. The symptom I was seeing was constant GC and a gradual ramping up of the CPU usage to the point where the app became unstable. Tracing back from that symptom took a lot of work, but once I identified it, we were able to switch away from file store caching, and so far things look good.
My takeaway from this is that even when you're constructing your application from prebuilt blocks, it really helps to have the expertise to dig into the architecture of the blocks themselves. Software components aren't Lego blocks, and although you'll want to use them (because you don't have the time or money to write your own search engine from scratch) you do need to be able to understand them in a pinch. It also really pays to work with open source components. I didn't have to spend weeks feeding bug reports to a vendor to help them fix our Mulgara problem. A handful of emails and a about a day's worth of work (spread over the course of a week) were enough to get me to the source of the problem and a fix for it (a 1-liner, incidentally).
Monday, May 10, 2010
#alt-ac Careers: Digital Humanities Developer
(part 1 of a series)
I've been a digital humanities developer, that is, someone who writes code, does interface and system design, and rescues data from archaic formats in support of DH projects in a few contexts during the course of my career. I'll be writing a piece for Bethany Nowviskie's #alt-ac (http://nowviskie.org/2010/alt-ac/) volume this year. This is (mostly) not that piece, though portions of it may appear there, so it's maybe part of a draft. This is an attempt to dredge up bits of my perspective as someone who has had an alternate-academic career (on and off) for the last decade. It's fairly narrowly aimed at people like me, who've done advanced graduate work in the Humanities, have an interest in Digital Humanities, and who have or are thinking about jobs that employ their technical skills instead of pursuing a traditional academic career.
A couple of future installments I have in mind are "What Skills Does a DH Developer Need?" and "What's Up with Digital Classics?"
In this installment, I'm going to talk about some of the environments I've worked in. I'm not going to pull punches, and this might get me into trouble, but I think that if there is to be a future for people like me, these things deserve an airing. If your institution is more enlightened than what I describe, please accept my congratulations and don't take offense.
In general, libraries are a really good place to work as a programmer, especially doing DH projects. I've spent the last three years working in digital library programming groups. There are some downsides to be aware of: Libraries are very hierarchical organizations, and if you are not a librarian then you are probably in a lower "caste". You will likely not get consistent (or perhaps any) support for professional development, conference attendance, etc. Librarians, as faculty, have professional development requirements as part of their jobs. You, whose professional development is not mandated by the organization (merely something you have to do if you want to stay current and advance your career), will not get the same level of support and probably won't get any credit for publishing articles, giving papers, etc. This is infuriating, and in my opinion self-defeating on the part of the institution, but it is an unfortunate fact.
[Note: Bethany Nowviskie informs me that this is not the case at UVA, where librarians and staff are funded at the same level for professional development. I hope that signals a trend. And by the way, I do realize I'm being inflammatory, talking of castes. This should make you uncomfortable.]
Another downside is that as a member of a lower caste, you may not be able to initiate projects on your own. At many insitutions, only faculty (including librarians) and higher level administrators can make grant proposals, so if you come up with a grant-worthy project idea, someone will have to front for you (and get the credit).
There do exist librarian/developer jobs, and this would be a substantially better situation from a professional standpoint, but since librarian jobs typically require a Master's degree in Library and/or Information Science, libraries may make the calculation that they would be excluding perfectly good programmers from the job pool by putting that sort of requirement in. These are not terribly onerous programs on the whole, should you want to get an MLIS degree, but it does mean obtaining another credential. For what it's worth, I have one, but have never held a librarian position.
It's not all bad though: you will typically have a lot of freedom, loose deadlines, shorter than average work-weeks, and the opportunity to apply your skills to really interesting and hard problems. If you want to continue to pursue your academic interests however, you'll be doing it as a hobby. They don't want your research agenda unless you're a librarian. In a lot of ways, being a DH developer in a library is a DH developer's nirvana. I rant because it's so close to ideal.
My first full time, permanent position post-Ph.D. was working for an IT organization that supports the College of Arts and Sciences at UNC Chapel Hill. I was one of a handful of programmers who did various kinds of administrative and faculty project support. It was a really good environment to work in. I got to try out new technologies, learned Java, really understood XSLT for the first time, got good at web development and had a lot of fun. I also learned to fear unfunded mandates, that projects without institutional support are doomed, and that if you're the last line of support for a web application, you'd better get good at making it scale.
IT organizations typically pay a bit better than, say, libraries and since it's an IT organization they actually understand technology and what it takes to build systems. There's less sense of being the odd man out in the organization. That said, if you're the academic/DH applications developer it's really easy to get overextended, and I did a bad job of avoiding that fate, "learning by suffering" as Aeschylus said.
Working outside academia as a developer is a whole other world. Again, DH work is likely to have to be a hobby, but depending on where you work, it may be a relevant hobby. You will be paid (much) more, will probably have a budget for professional development, and may be able to use it for things such as attending DH conferences. Downsides are that you'll probably work longer hours and you'll have less freedom to choose what you do and how you do it, because you're working for an organization that has to make money. The capitalist imperative may strike you as distasteful if you've spent years in academia, but in fact it can be a wonderful feedback mechanism. Doing things the right way (in general) makes the organization money, and doing them wrong (again, in general) doesn't. It can make decision-making wonderfully straightforward. Companies, particularly small ones, can make decisions with a speed that seems bewilderingly quick when compared to libraries, which thrive on committees and meetings and change direction with all the flexibility of a supertanker.
Another advantage of working in industry is that you are more likely to be part of a team working on the same stuff as you. In DH we tend to only be able to assign one or two developers to a job. You will likely be the lone wolf on a project at some point in your career. Companies have money, and they want to get stuff done, so they hire teams of developers. Being on a team like this is nice, and I often miss it.
There are lots of companies that work in areas you may be interested in as someone with a DH background, including the semantic web, text mining, linked data, and digital publishing. In my opinion, working on DH projects is great preparation for a career outside academia.
As a DH developer, you will more likely than not end up working on grant-funded projects, where your salary is paid with "soft money". What this means in practical terms is that your funding will expire at a certain date. This can be good. It's not uncommon for programmers to change jobs every couple of years anyway, so a time-limited position gives you a free pass at job-switching without being accused of job-hopping. If you work for an organization that's good at attracting funding, then it's quite possible to string projects together and/or combine them. Though there can be institutional impedance mismatch problems here, in that it might be hard to renew a time-limited position, or to convert it to a permanent job without re-opening it for new applicants, or to fill in the gaps between funding cycles. So some institutions have a hard time mapping funding streams onto people efficiently. These aren't too hard to spot because they go though "boom and bust" cycles, staffing up to meet demand and then losing everybody when the funding is gone. This doesn't mean "don't apply for this job," just do it with your eyes open. Don't go in with the expectation (or even much hope) that it will turn into a permanent position. Learn what you can and move on. The upside is that these are often great learning opportunities.
In sum, being a DH developer is very rewarding. But I'm not sure it's a stable career path in most cases, which is a shame for DH as a "discipline" if nothing else. It would be nice if there were more senior positions for DH "makers" as well as "thinkers" (not that those categories are mutually exclusive). I suspect that the institutions that have figured this out will win the lion's share of DH funding in the future, because their brain trusts will just get better and better. The ideal situation (and what you should look for when you're looking to settle down) is a place
For the most part, though, DH development may be the kind of thing you do for a few years while you're young before you go and do something else. I often wonder whether my DH developer expiration date is approaching. Grant funding often won't pay enough for an experienced programmer, unless those who wrote the budget knew what they were doing [Note: I've read too many grant proposals where the developer salary is < $50K (entry-level) but they have the title "Lead Developer" vel sim.— for what it's worth, this positively screams "We don't know what we're doing!"]. It may soon be time to go back to working for lots more money in industry; or to try to get another administrative DH job. For now, I still have about a year's worth of grant funding left. Better get back to work.
I've been a digital humanities developer, that is, someone who writes code, does interface and system design, and rescues data from archaic formats in support of DH projects in a few contexts during the course of my career. I'll be writing a piece for Bethany Nowviskie's #alt-ac (http://nowviskie.org/2010/alt-ac/) volume this year. This is (mostly) not that piece, though portions of it may appear there, so it's maybe part of a draft. This is an attempt to dredge up bits of my perspective as someone who has had an alternate-academic career (on and off) for the last decade. It's fairly narrowly aimed at people like me, who've done advanced graduate work in the Humanities, have an interest in Digital Humanities, and who have or are thinking about jobs that employ their technical skills instead of pursuing a traditional academic career.
A couple of future installments I have in mind are "What Skills Does a DH Developer Need?" and "What's Up with Digital Classics?"
In this installment, I'm going to talk about some of the environments I've worked in. I'm not going to pull punches, and this might get me into trouble, but I think that if there is to be a future for people like me, these things deserve an airing. If your institution is more enlightened than what I describe, please accept my congratulations and don't take offense.
Working for Libraries
In general, libraries are a really good place to work as a programmer, especially doing DH projects. I've spent the last three years working in digital library programming groups. There are some downsides to be aware of: Libraries are very hierarchical organizations, and if you are not a librarian then you are probably in a lower "caste". You will likely not get consistent (or perhaps any) support for professional development, conference attendance, etc. Librarians, as faculty, have professional development requirements as part of their jobs. You, whose professional development is not mandated by the organization (merely something you have to do if you want to stay current and advance your career), will not get the same level of support and probably won't get any credit for publishing articles, giving papers, etc. This is infuriating, and in my opinion self-defeating on the part of the institution, but it is an unfortunate fact.
[Note: Bethany Nowviskie informs me that this is not the case at UVA, where librarians and staff are funded at the same level for professional development. I hope that signals a trend. And by the way, I do realize I'm being inflammatory, talking of castes. This should make you uncomfortable.]
Another downside is that as a member of a lower caste, you may not be able to initiate projects on your own. At many insitutions, only faculty (including librarians) and higher level administrators can make grant proposals, so if you come up with a grant-worthy project idea, someone will have to front for you (and get the credit).
There do exist librarian/developer jobs, and this would be a substantially better situation from a professional standpoint, but since librarian jobs typically require a Master's degree in Library and/or Information Science, libraries may make the calculation that they would be excluding perfectly good programmers from the job pool by putting that sort of requirement in. These are not terribly onerous programs on the whole, should you want to get an MLIS degree, but it does mean obtaining another credential. For what it's worth, I have one, but have never held a librarian position.
It's not all bad though: you will typically have a lot of freedom, loose deadlines, shorter than average work-weeks, and the opportunity to apply your skills to really interesting and hard problems. If you want to continue to pursue your academic interests however, you'll be doing it as a hobby. They don't want your research agenda unless you're a librarian. In a lot of ways, being a DH developer in a library is a DH developer's nirvana. I rant because it's so close to ideal.
Working for a .edu IT Organization
My first full time, permanent position post-Ph.D. was working for an IT organization that supports the College of Arts and Sciences at UNC Chapel Hill. I was one of a handful of programmers who did various kinds of administrative and faculty project support. It was a really good environment to work in. I got to try out new technologies, learned Java, really understood XSLT for the first time, got good at web development and had a lot of fun. I also learned to fear unfunded mandates, that projects without institutional support are doomed, and that if you're the last line of support for a web application, you'd better get good at making it scale.
IT organizations typically pay a bit better than, say, libraries and since it's an IT organization they actually understand technology and what it takes to build systems. There's less sense of being the odd man out in the organization. That said, if you're the academic/DH applications developer it's really easy to get overextended, and I did a bad job of avoiding that fate, "learning by suffering" as Aeschylus said.
Working in Industry
Working outside academia as a developer is a whole other world. Again, DH work is likely to have to be a hobby, but depending on where you work, it may be a relevant hobby. You will be paid (much) more, will probably have a budget for professional development, and may be able to use it for things such as attending DH conferences. Downsides are that you'll probably work longer hours and you'll have less freedom to choose what you do and how you do it, because you're working for an organization that has to make money. The capitalist imperative may strike you as distasteful if you've spent years in academia, but in fact it can be a wonderful feedback mechanism. Doing things the right way (in general) makes the organization money, and doing them wrong (again, in general) doesn't. It can make decision-making wonderfully straightforward. Companies, particularly small ones, can make decisions with a speed that seems bewilderingly quick when compared to libraries, which thrive on committees and meetings and change direction with all the flexibility of a supertanker.
Another advantage of working in industry is that you are more likely to be part of a team working on the same stuff as you. In DH we tend to only be able to assign one or two developers to a job. You will likely be the lone wolf on a project at some point in your career. Companies have money, and they want to get stuff done, so they hire teams of developers. Being on a team like this is nice, and I often miss it.
There are lots of companies that work in areas you may be interested in as someone with a DH background, including the semantic web, text mining, linked data, and digital publishing. In my opinion, working on DH projects is great preparation for a career outside academia.
Funding
As a DH developer, you will more likely than not end up working on grant-funded projects, where your salary is paid with "soft money". What this means in practical terms is that your funding will expire at a certain date. This can be good. It's not uncommon for programmers to change jobs every couple of years anyway, so a time-limited position gives you a free pass at job-switching without being accused of job-hopping. If you work for an organization that's good at attracting funding, then it's quite possible to string projects together and/or combine them. Though there can be institutional impedance mismatch problems here, in that it might be hard to renew a time-limited position, or to convert it to a permanent job without re-opening it for new applicants, or to fill in the gaps between funding cycles. So some institutions have a hard time mapping funding streams onto people efficiently. These aren't too hard to spot because they go though "boom and bust" cycles, staffing up to meet demand and then losing everybody when the funding is gone. This doesn't mean "don't apply for this job," just do it with your eyes open. Don't go in with the expectation (or even much hope) that it will turn into a permanent position. Learn what you can and move on. The upside is that these are often great learning opportunities.
In sum, being a DH developer is very rewarding. But I'm not sure it's a stable career path in most cases, which is a shame for DH as a "discipline" if nothing else. It would be nice if there were more senior positions for DH "makers" as well as "thinkers" (not that those categories are mutually exclusive). I suspect that the institutions that have figured this out will win the lion's share of DH funding in the future, because their brain trusts will just get better and better. The ideal situation (and what you should look for when you're looking to settle down) is a place
- that has a good track record of getting funded,
- where developers are first-class members of the organization (i.e. have "researcher" or similar status),
- where there's a team in place and it's not just you, and
- where there's some evidence of long-range planning.
For the most part, though, DH development may be the kind of thing you do for a few years while you're young before you go and do something else. I often wonder whether my DH developer expiration date is approaching. Grant funding often won't pay enough for an experienced programmer, unless those who wrote the budget knew what they were doing [Note: I've read too many grant proposals where the developer salary is < $50K (entry-level) but they have the title "Lead Developer" vel sim.— for what it's worth, this positively screams "We don't know what we're doing!"]. It may soon be time to go back to working for lots more money in industry; or to try to get another administrative DH job. For now, I still have about a year's worth of grant funding left. Better get back to work.
Tuesday, May 04, 2010
Addenda et Corrigenda
The proceedings of the 2009 Lawrence J. Schoenberg Symposium on Manuscript Studies in the Digital Age, at which I was a panelist were recently published at http://repository.upenn.edu/ljsproceedings/. I contributed a short piece arguing for the open licensing of content related to the study of medieval manuscripts.
Peter Hirtle, Senior Policy Advisor at the Cornell University Library, wrote me a message commenting on the piece and raising a point that I had elided (reproduced with permission):
Peter is quite right that the copyright situation in the US, at least insofar as faithful digital reproductions of manuscript pages are concerned, is (with high probability) governed by the 1999 Bridgeman vs. Corel decision. So it is arguably best practice for a scholar who has photographed manuscripts to publish them and assert that they are in the public domain.
I skimmed over this in my article because, for one thing, much of the scholarly content of the symposium dealt with European institutions and their online publication (some behind a paywall—sometimes a crazily expensive one) of manuscripts, so US copyright law doesn't necessarily pertain. For another, I had in mind not just manuscripts but inscriptions, to which—to the extent that they are three-dimensional objects—Bridgeman doesn't pertain. Finally, while it is common practice to produce faithful digital reproductions of manuscript texts, it is also common to enhance those images for the sake of readability, at which point they are (may be?) no longer "slavish reproductions" and thus subject to copyright. The problem of course, as so often in copyright, is that there's no case law to back this up. If I crank up the contrast or run a Photoshop (or Gimp) filter on an image, have I altered it sufficiently to make it copyrightable? I don't know for certain, and I'm not sure anyone does. So on balance I'd still argue for doing the simple thing and putting a Creative Commons license (CC-BY is my recommendation) on everything. This is what the Archimedes Palimpsest project does, for example, who are arguably in just this situation with their publication of multispectral imaging of the palimpsest. And they are to be commended for doing so.
Anyway, I'd like to thank Peter, first for reading my article and second for prodding me into usefully complicating something I had oversimplified for the sake of argument.
Peter Hirtle, Senior Policy Advisor at the Cornell University Library, wrote me a message commenting on the piece and raising a point that I had elided (reproduced with permission):
Dear Dr. Cayless:
I read with great interest your article on “Digitized Manuscripts and Open Licensing.” Your arguments in favor of a CC-BY license for medieval scholarship are unusual, important, and convincing.
I was troubled, however, to see your comments on reproductions of medieval manuscripts. For example, you note that if you use a CC-BY license, “an entrepreneur can print t-shirts using your digital photograph of a nice initial from a manuscript page.” Later you add:
"Should reproductions of cultural objects that have never been subject to copyright (and that would no longer be, even if they once had) themselves be subject to copyright? The fact is that they are, and some uses of the copyright on photographs may be laudable, for example a museum or library funding its ongoing maintenance costs by selling digital or physical images of objects in its collection, but the existence of such examples does not provide an answer to the question: as an individual copyright owner, do you wish to exert control how other people use a photograph of something hundreds or thousands or years old?"
There is a fundamental mistaken concept here. While some reproductions of cultural objects are subject to copyright, most aren’t. Ever since the Bridgeman decision, the law in the New York circuit at least (and we believe in most other US courts) is that a “slavish” reproduction does not have enough originality to warrant its own copyright protection. If it is an image of a three-dimensional object, there would be copyright, but if it is just a reproduction of a manuscript page, there would be no copyright. It may take great skill to reproduce well a medieval manuscript, but it does not take originality. To claim that it does encourages what has been labeled as “copyfraud.”
You can read more about Bridgeman on pps. 34-35 in my book on Copyright and Cultural Institutions: Guidelines for Digitization for U.S. Libraries, Archives, and Museums, available for sale from Amazon and as a free download from SSRN at http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1495365.
Sincerely,
Peter Hirtle
Peter is quite right that the copyright situation in the US, at least insofar as faithful digital reproductions of manuscript pages are concerned, is (with high probability) governed by the 1999 Bridgeman vs. Corel decision. So it is arguably best practice for a scholar who has photographed manuscripts to publish them and assert that they are in the public domain.
I skimmed over this in my article because, for one thing, much of the scholarly content of the symposium dealt with European institutions and their online publication (some behind a paywall—sometimes a crazily expensive one) of manuscripts, so US copyright law doesn't necessarily pertain. For another, I had in mind not just manuscripts but inscriptions, to which—to the extent that they are three-dimensional objects—Bridgeman doesn't pertain. Finally, while it is common practice to produce faithful digital reproductions of manuscript texts, it is also common to enhance those images for the sake of readability, at which point they are (may be?) no longer "slavish reproductions" and thus subject to copyright. The problem of course, as so often in copyright, is that there's no case law to back this up. If I crank up the contrast or run a Photoshop (or Gimp) filter on an image, have I altered it sufficiently to make it copyrightable? I don't know for certain, and I'm not sure anyone does. So on balance I'd still argue for doing the simple thing and putting a Creative Commons license (CC-BY is my recommendation) on everything. This is what the Archimedes Palimpsest project does, for example, who are arguably in just this situation with their publication of multispectral imaging of the palimpsest. And they are to be commended for doing so.
Anyway, I'd like to thank Peter, first for reading my article and second for prodding me into usefully complicating something I had oversimplified for the sake of argument.
Subscribe to:
Posts (Atom)