Issue #1
Search results in the PN are supposed to return with KWIC snippets, highlighting the search terms. As part of the move, I upgraded Lucene to the latest release (2.4.1). The Lucene in the PN was 2.3.x, but the developer at Columbia had worked hard to eke as much indexing speed out of it as possible, and had imported code from the 2.4 branch, with some modifications. Since this code was really close to 2.4, I'd had reason to hope the upgrade would be smooth, and it mostly was. Highlighting wasn't working for Greek though, even though the search itself was...
Debugging this was really hard, because as it turned out, there was no failure in any of the running code. It just wasn't running the right code. A couple of the slightly modified Lucene classes in the PN codebase were being stepped on by the new Lucene because instead of a jar named "ddbdp.jar", the new PN jars were named after the project in which they resided (so, "pn-ddbdp-indexers.jar". And they were getting loaded after Lucene instead of before. Not the first time I'd seen this kind of problem, but always a bit baffling. In the end I moved the PN Lucene classes out of the way by changing their names and how they were called.
Issue #2
This one was utterly baffling as well. Lemmatized search (that is, searching for dictionary headwords and getting hits on all the forms of the word—very useful for inflected languages, like Greek) was working at Columbia, and not at NYU. Bizarre. I hadn't done anything to the code. Of course, it was my fault. It almost always is the programmer's fault. A few months before, in response to a bug report (and before I started working for NYU), I had updated the transcoder software (which converts between various encodings for Ancient Greek) to conform to the recommended practice for choosing which precomposed (letter + accent) character to use when the same one (e.g. alpha + acute accent) occurs in both the Greek (Modern) and Greek Extended (Ancient) blocks in Unicode. Best practice is to choose the character from the Greek block, so \u03AC instead of \u1F71 for ά. Transcoder used to use the Greek Extended character, but since late 2008 it has followed the new recommendation and used characters from the Greek block, where available. Unfortunately this change happened after transcoder had been used to build the lemma database that the PN uses to expand lemmatized queries. So it had the wrong characters in it, and a search for any lemma containing an acute accent would fail. Again, all the code was executing perfectly; some of the data was bad. It didn't help that when I pasted lemmas into Oxygen, it normalized the encoding, or I might have realized sooner that there were differences.
Issue #3
Last, but not least, was a bug which manifested as a failure in certain types of search. "A followed by B within n places" searches worked, but "A and B (not in order) within n places" and "A but not B within n places" both failed. Again, no apparent errors in the PN code. The NullPointerException that was being thrown came from within the Lucene code! After a lot of messing about, I was able to determine that the failure was due to a Lucene change that the PN code wasn't implementing against. Once I'd found that, all it took to fix it was to override a method from the Lucene code. This was actually a Lucene bug (https://issues.apache.org/jira/browse/LUCENE-1748) which I reported. In trying to maintain backward compatibility, they had kept compile-time compatibility with pre-2.4 code, but broken it in execution. I have to say, I was really impressed with how fast the Lucene team, particularly Mark Miller, responded. The bug is already fixed.
So, lessons learned:
- Tests are good. I didn't have any available for the project that contained all of the bugs listed here. They exist (though coverage is spotty), but there are dependencies that are tricky to resolve, and I had decided to defer getting the tests to work in favor of getting the PN online. Not having tests ate into the time I'd saved by deferring them.
- In both cases #1 and #3, I had to find the problem by reading the code and stepping through it in my head. Practice this basic skill.
- Look for ways your architecture may have changed during the upgrade. Anything may be significant, including filenames.
- Greek character encoding is the Devil (but I already knew that).
- It's probably your fault, but it might not be. Look closely at API changes in libraries you upgrade. Go look at the source if anything looks fishy. I didn't expect to find anything wrong with something as robust as Lucene, but I did.
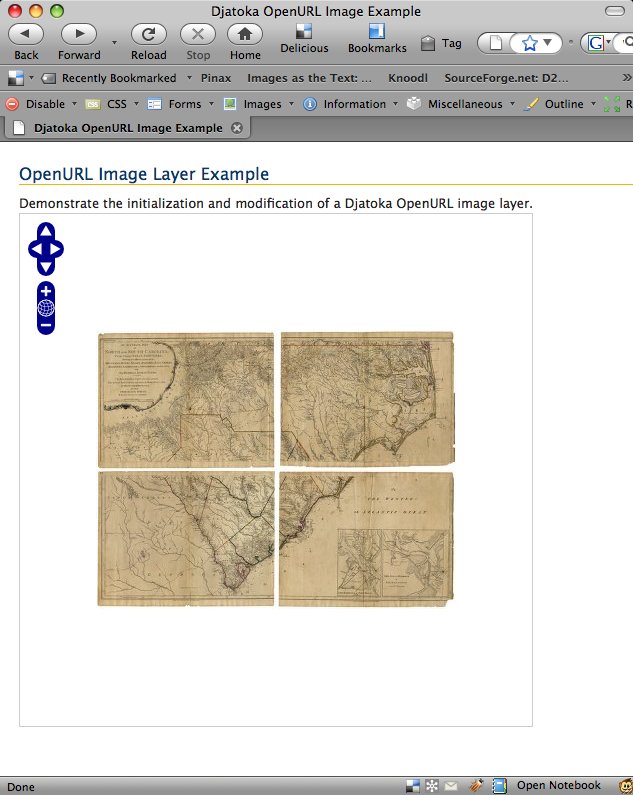
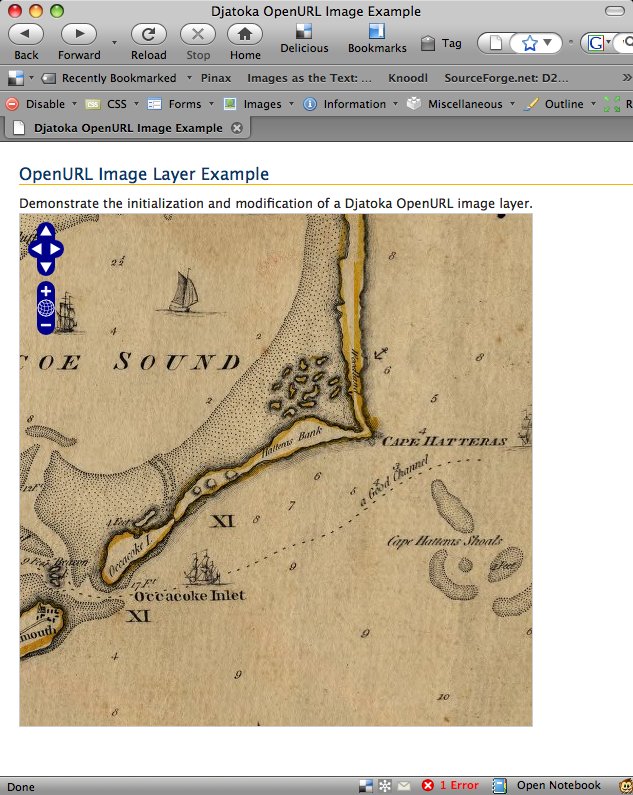
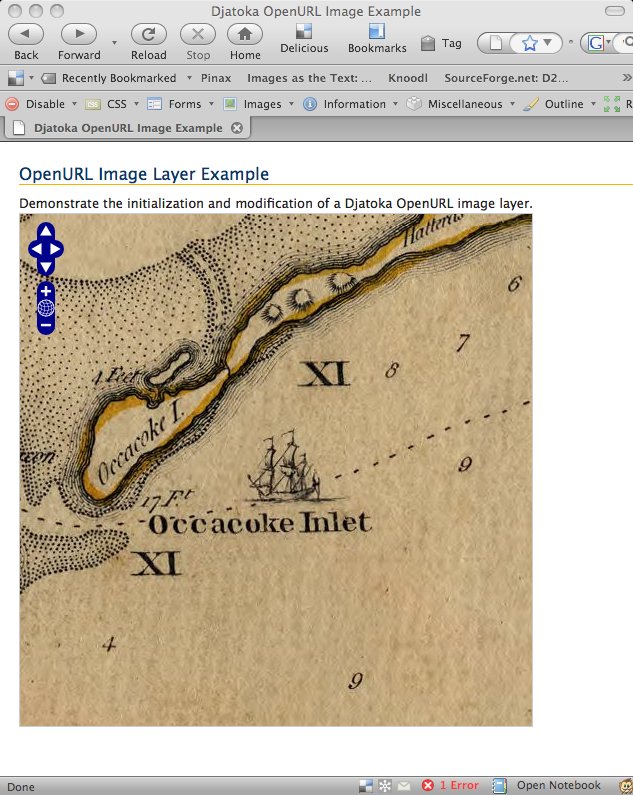
{kind=link}